(Ảnh: Shutterstock)
Bộ máy tổng hợp protein của tế bào đọc và hiểu các mã di truyền tùy theo “hoàn cảnh”, tương tự như cách con người đọc và hiểu các từ đồng âm theo ngữ cảnh, ví dụ “ruồi đậu trên mâm xôi đậu”, “kiến bò lên đĩa thịt bò”…
Tiếp theo Phần 2.
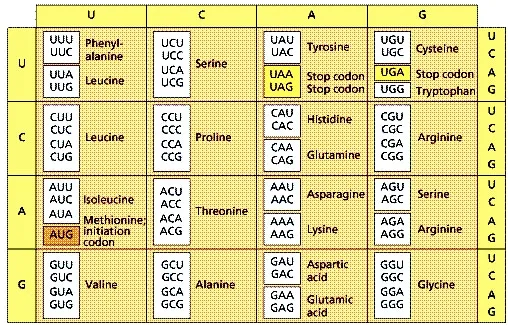
Như đã trình bày ở Phần 2, theo lý thuyết kết cặp bazơ linh hoạt (wobble hypothesis) của Francis Crick (nhà bác học đoạt giải Nobel nhờ khám phá ra cấu trúc DNA), có đến 8 trong 64 mã di truyền bộ 3 có khả năng gây ra nhầm lẫn về loại axit amin được tổng trong quá dịch mã (tương ứng với xác suất 6,25%).
Nhưng vì sao bộ máy tổng hợp protein của tế bào (ribosome) trên thực tế không mắc bất kỳ lỗi nào trong việc lựa chọn axit amin mà quá trình di truyền và sinh trưởng của sinh vật cần sử dụng?
Câu trả lời là: bộ gen của sinh vật thực chất là một hệ thống văn bản được viết bằng ngôn ngữ thông minh, hoạt động theo các quy tắc giống như quy tắc ngôn ngữ của con người. Các bộ phận của tế bào có thể đọc và hiểu ngôn ngữ này để thực hiện quá trình di truyền, sinh sản và phát triển của sinh vật.
Hiện tượng đồng nghĩa trong mã di truyền
Trong ngôn ngữ học, từ “đồng nghĩa” được xác định là những từ có hình thức ngữ âm (viết, đọc) khác nhau nhưng lại có nghĩa giống nhau (ví dụ bố, cha, tía..) hoặc gần giống nhau (chết, hy sinh, toi mạng…).
Hiện tượng các mã di truyền (codon) “đồng nghĩa” vốn đã được phát hiện và thừa nhận từ lâu trong việc phân tích các mã di truyền. Tức là có 2, 3 thậm chí 4 mã di truyền khác nhau cùng mã hóa một loại 1 axit amin. Bảng 1 cho thấy có ít nhất 22 nhóm mã di truyền xuất hiện hiện tượng đồng nghĩa.
Hiện tượng đồng âm trong mã di truyền
Trong bảng mã bộ 3 di truyền, cũng xuất hiện hiện tượng “đồng âm”, nghĩa là một mã di truyền có được dịch thành 2 loại axit amin khác nhau.
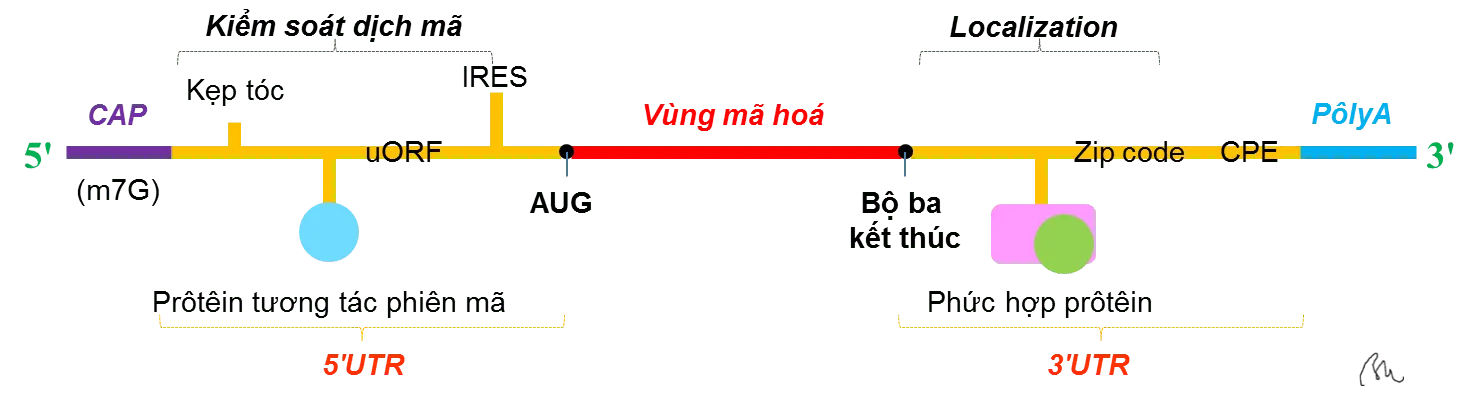
Năm 1998, nhà sinh học phân tử nổi tiếng của Nga L. P. Ovchinnikov đã phát hiện rằng: Trong hầu hết sinh vật nhân chuẩn (bao gồm cả con người), mã bộ 3 AUG được xác định là mã khởi đầu, tuy nhiên nó chỉ là mã khởi đầu nếu có bazơ A hoặc G xuất hiện trước nó 2 vị trí, và bazơ xuất hiện ngay sau nó là G. Ví dụ AUCAUGG hoặc GCUAUGG. Nếu mã AUG đầu tiên trong mRNA không xuất hiện trong hoàn cảnh tối ưu thì nó sẽ bị bỏ qua và quá trình dịch mã sẽ bắt đầu với mã AUG tiếp theo. Đoạn mã mRNA sẽ được quét từ đầu phần đầu của nó để tìm kiếm vị trí mã AUG trong hoàn cảnh tối ưu của cần có. [1]
L. P. Ovchinnikov còn có một phát hiện thứ 2 rất quan trọng, đó là có một nhân tố gây ảnh hưởng từ xa bởi một vài đoạn ở xa của mRNA (đoạn khởi đầu (cap), đoạn đuôi poly-A và đoạn không được dịch mã (untranslated region-UTR) của mRNA) đến việc ribosome tích hợp các axit amin đầu tiên thành chuỗi petit tổng hợp. Điều này dẫn đến ý tưởng đọc quét toàn bộ (read through) mRNA, tức là xem xét hoàn cảnh của mRNA. [2]
Trong các thí nghiệm, L. P. Ovchinnikov cũng phát hiện rằng việc đọc mRNA của một đoạn cistron đơn lẻ (một đoạn ADN xác định một chuỗi polipeptit riêng lẻ của một phân tử protein) không phải lúc nào cũng xảy ra liên tục. Ban đầu người ta cho rằng trình tự các bazơ trong mRNA luôn được đọc liên tục từ mã codon khởi đầu đến mã kết thúc. Tuy nhiên, trong quá trình dịch mRNA của của đoạn gen của thể thực khuẩn T4 (Phage T4 Gene 0) Ovchinnikov phát hiện rằng 1 đoạn mã di truyền dài đáng kể có thể bị bỏ qua. Trong trường hợp này, một ribosome thực hiện một cú nhảy cóc vượt qua 50 bazơ dọc theo mRNA từ một mã codon GGA xác định axit amin glycine được đặt phía trước một mã kết thúc UAG đến một mã codon GGA khác. Cơ thể giải thích hiện tượng này vẫn chưa được xác định rõ ràng [3]
Năm 2009, Tiến sĩ Anton A Turanov tại Đại học Nebraska, Hoa Kỳ và các cộng sự đã có phát hiện rằng codon kết thúc UGA có thể mã hóa 2 axit amin khác nhau là selenocysteine (Se) hặc cysteine (Cys). Trong phát hiện này, axit min được lựa chọn được xác định bởi đoạn không được dịch mã 3’UTR (untranslated region-UTR) cụ thể và vị trí của codon chức năng kép này trong mRNA. [4]
Năm 2016, Tiến sĩ Julia Hofhuis và các đồng sự tại Trung tâm Y tế, Đại học Göttingen, Đức phát hiện rằng: trong quá trình đọc đọc quét toàn bộ (read through) đoạn gen mở rộng MHD1x, codon kết thúc UGA đồng thời có thể mã hóa cả protein arginine (Arg) lẫn protein tryptophan (Trp). [5]
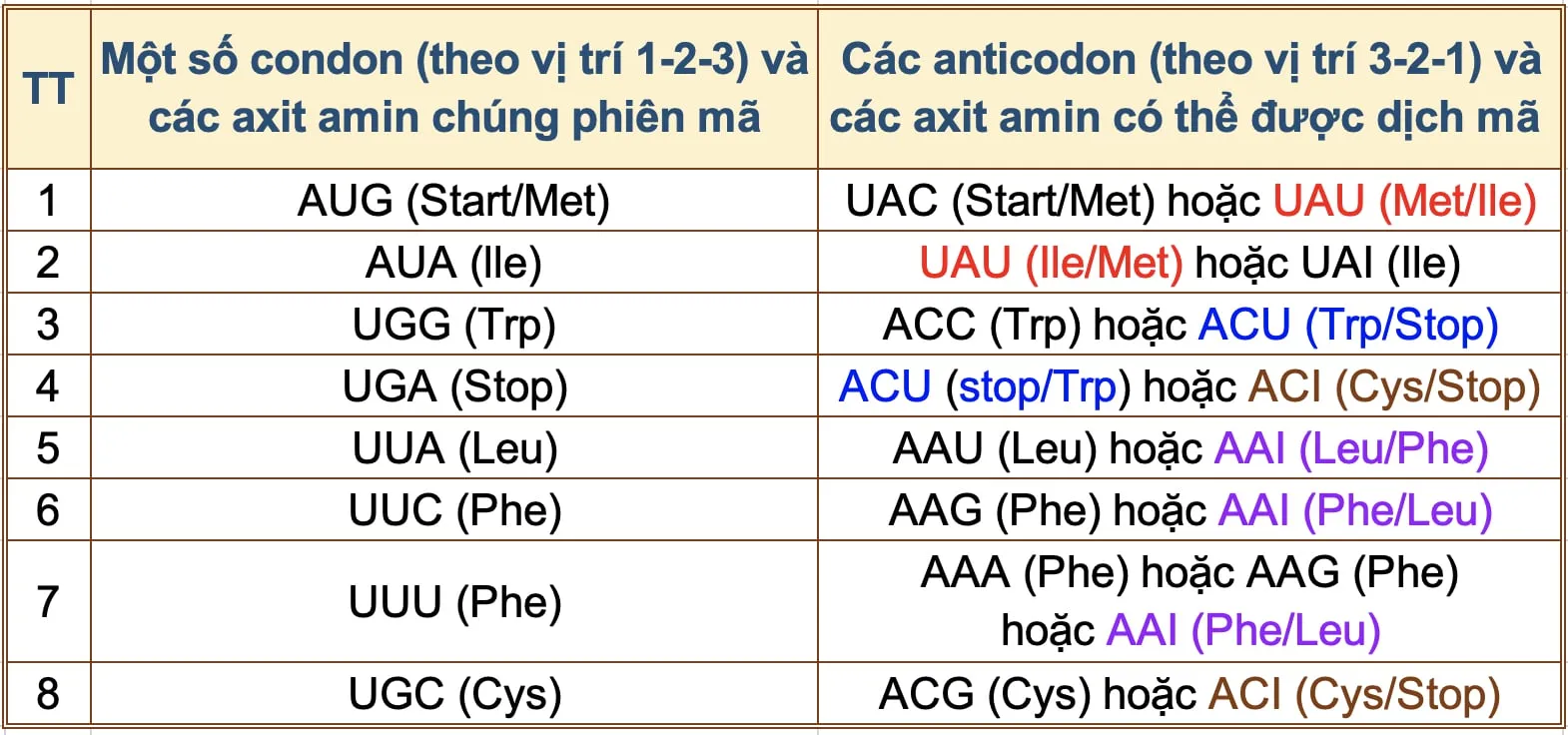
Theo ngôn ngữ học, nghĩa của các từ đồng âm chỉ được xác định dựa vào hoàn cảnh và vị trí xuất hiện của nó, ví dụ “ruồi đậu trên mâm xôi đậu”, “kiến bò lên đĩa thịt bò”, “con ngựa đá con ngựa đá”… Các phát hiện về ý nghĩa thông tin của mã khởi đầu (AUG) và mã kết thúc (UGA) cần dựa vào vị trí chính xác của nó, hoặc có thêm thông tin hướng dẫn từ vùng không được dịch mã (UTR) hoặc việc phải đọc quét toàn bộ mRNA để xác định ý nghĩa của codon khiến chúng ta liên tưởng đến việc 2 mã codon khởi đầu và kết thúc trong bảng 2 chính là 2 từ có hiện tượng đồng âm.
Không chỉ các mã khởi đầu và kết thúc, bảng 2 cho ta thấy có ít nhất 6 mã bộ 3 khác cũng là các từ “đồng âm”. Cho đến nay, chúng ta chưa có thông tin xác định vì sao tế bào hiểu được ý nghĩa của các từ đồng âm này, nhưng chúng ta biết rằng quá trình tổng hợp protein và di truyền hầu như không xuất hiện bất cứ một sai lệch nào hết.
Vậy chắc hẳn các mã bộ 3 có từ đồng âm này cũng phải tuân thủ các nguyên tắc nào đó của ngôn ngữ thông minh và bộ phận dịch mã thông minh của ribosome phải đọc và hiểu toàn bộ các từ của mRNA thậm chí là phần lớn hơn mRNA để đưa ra quyết định chính xác để 1) lựa chọn bộ đôi codon-anticodon đồng âm nào phù hợp, mã hóa các axit amin khác và/hoặc thực hiện việc kết thúc mã hóa hay 2) quyết định nhảy 1 khoảng cách nhất định dọc theo sợi mRNA.
Giáo sư Peter Gariaev, người nhiều năm nghiên có các nghiên cứu sâu về bộ gen cũng như khả năng ngôn ngữ của bộ gen cho rằng các phân tử DNA, RNA, enzyne, ribosome, axit amin và các chất chuyển hóa khác là những cấu trúc vật chất thông minh ở mức độ đơn giản (quasi-intelligent system), chúng có ngôn ngữ là ngôn ngữ di truyền giống như ngôn ngữ của con người và giao tiếp với nhau qua ngôn ngữ này.
Vai trò của DNA “rác”
Ta biết rằng bộ gen của các sinh vật hay các phân tử DNA gồm 2 nhóm chính: nhóm DNA có thể mã hóa ra protein, nhóm DNA không mã hóa protein, được cho là chỉ đóng vai trò tín hiệu điều hòa hoặc kiểm soát hoạt động của các gen, và bị gọi là DNA “rác”.
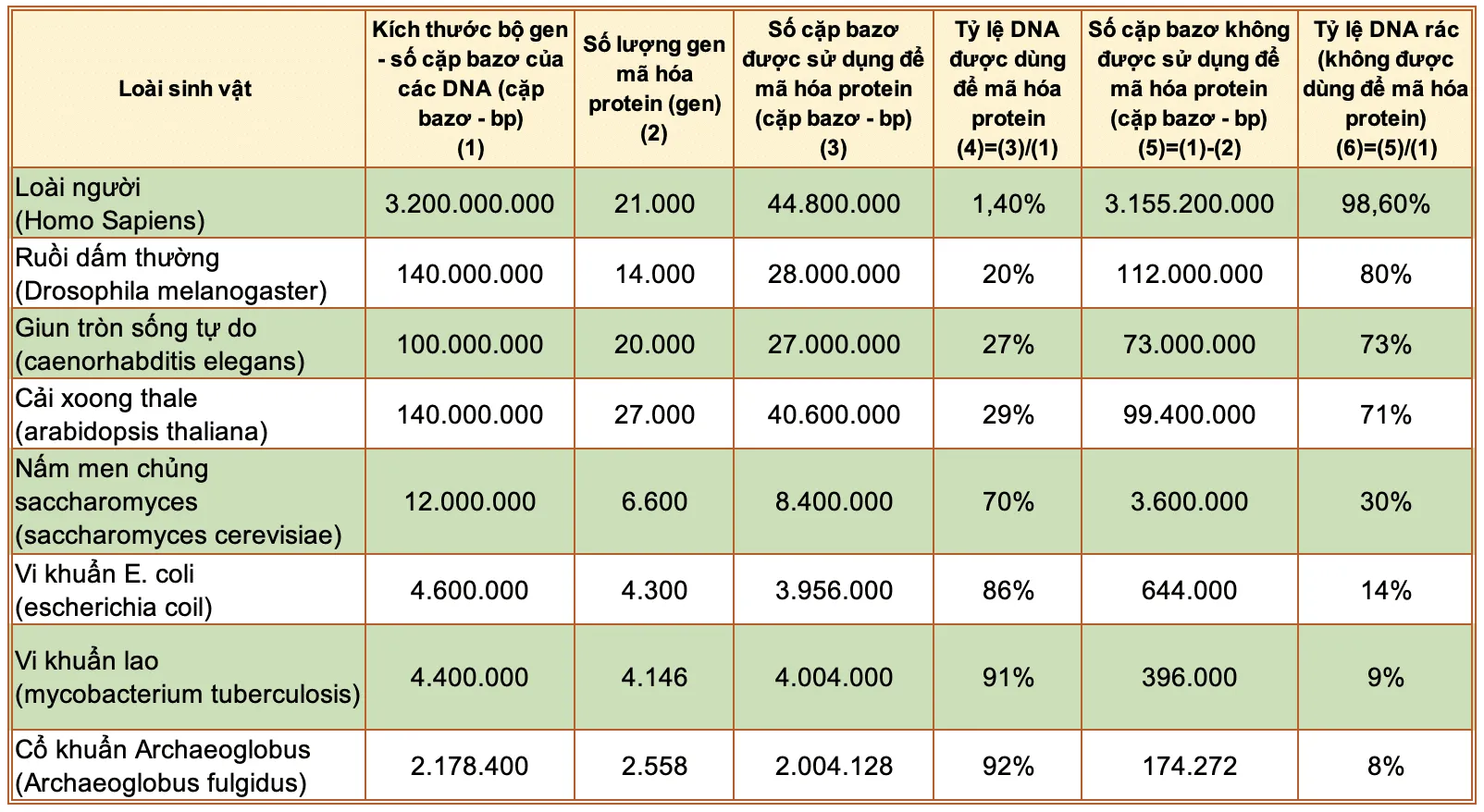
Có một điều cần chú ý là số lượng gen mã hóa protein là không quá khác biệt giữa các sinh vật có mức độ phức tạp khác nhau, có nghĩa là số lượng DNA để mã hóa protein giữa các sinh vật có mực độ phức tạp khác nhau là không quá khác biệt.
Tuy vậy, có một điều kỳ lạ khác là sinh vật càng phức tạp thì có tỷ lệ DNA “rác” trên tổng số DNA càng lớn, ngược lại sinh vật càng đơn giản thì tỷ lệ DNA “rác” càng thấp. Ví dụ, tỷ lệ DNA “rác” của người là khoảng 98,6%, của ruồi dấm thường là 80%, của nấm men là 30% và của vi khuẩn lao là 9%. Điều này cũng có nghĩa là số DNA “rác” của sinh vật càng phức tạp thì càng nhiều.
Theo thuyết tiến hóa, sinh vật càng tiến hóa, càng tinh vi thì những thứ thừa thãi, không cần thiết càng cần phải bị đào thải. Nhưng thực tế là lượng DNA “rác” càng tăng theo mức độ “tiến hóa” của sinh vật. Điều này ngược với thuyết tiến hóa của Darwin.
Vậy chúng ta lý giải vai trò của các DNA “rác” như thế nào?
Năm 1994, nhà khoa học Rosario N. Mantegna và các đồng sự tại Đại học Boston, Hoa Kỳ đã có nghiên cứu và thu được nhiều bằng chứng cho việc giải thích tính chất ngôn ngữ của bộ gen.
Sử dụng định luật thống kê Zipf-Mandelbrot và áp dụng lý thuyết thông tin của Shannon vào nghiên cứu các vùng DNA mã hóa và DNA không mã hóa, kết quả của Mantegna cho thấy các vùng DNA không mã hóa giống ngôn ngữ tự nhiên hơn là các vùng mã hóa, và có thể, các trình tự không mã hóa của các phân tử di truyền là cơ sở cho một (hoặc nhiều) ngôn ngữ sinh học. [6]
Những phát hiện này cho thấy các DNA “rác” đóng vai trò vô cùng quan trọng trong quá trình di truyền của sinh vật. Dường như sinh vật càng phức tạp, các DNA “rác” càng được sử dụng nhiều hơn để tham gia vào quá trình di truyền của sinh vật.
Ta tạm thời giải thích vai trò của DNA mã hóa và DNA “rác” không mã hóa trong quá trình di truyền như sau:
Coi cơ thể sinh vật như một ngôi nhà, các DNA mã hóa protein chỉ đóng vai trò như các tài liệu hướng dẫn để tạo ra loại vật liệu xây dựng như gạch, đá, xi măng, gỗ, sắt, thép (tương ứng với các loại axit amin)… Còn toàn thể bộ gen của sinh vật bao gồm cả các DNA mã hóa và DNA không mã hóa có vai trò như một tài liệu thiết kế kiến trúc, nó hướng dẫn tế bào và các bộ phận di truyền của cơ thể biết cần xây ngôi nhà mấy tầng, bao nhiêu phòng, có sân trước hay không (tương ứng với loại sinh vật nào cần được tạo ra)… Tài liệu này cũng hướng dẫn tế bào và các bộ phận di truyền biết khi nào cần sử dụng loại vật liệu nào để xây móng nhà, khi nào cần sử dụng vật liệu khác để xây tường, chọn loại gạch lát nào để lát nền phòng khách, loại gạch lát nào để lát nền nhà tắm (tương ứng với việc tạo ra các bộ phận cần thiết của cơ thể)…
Các tài liệu, văn bản đặc biệt này được viết bằng ngôn ngữ thông minh, giống như ngôn ngữ của con người và được tế bào và hệ thống di truyền đọc, hiểu rõ và thực hiện theo ngữ cảnh của ngôn ngữ. Văn bản này hướng dẫn quá trình di truyền, sinh trưởng, phát triển hình thái của sinh vật. Điều này vượt qua phạm vi hiểu biết rằng quá trình di truyền chỉ là các quá trình của vật lý và hóa học.
Vậy điều gì đã tạo ra văn bản di truyền với ngôn ngữ thông minh như vậy, và làm sao để tế bào và các bộ phận của cơ thể có thể đọc và hiểu được các văn bản di truyền này? Mời quý độc giả đón xem tiếp ở Phần 4.
Thiện Tâm
Tài liệu tham khảo:
[1] Trang 37, Quantum Consciousness of the Linguistic-Wave Genome, theory and practice; Institute of Quantum Genetics, Peter Gariaev
[2] Trang 37, Quantum Consciousness of the Linguistic-Wave Genome, theory and practice; Institute of Quantum Genetics, Peter Gariaev
[3] Trang 37, Quantum Consciousness of the Linguistic-Wave Genome, theory and practice; Institute of Quantum Genetics, Peter Gariaev
[4] Genetic code supports targeted insertion of two amino acids by one codon, Anton A. Turanov, Alexey V. Lobanov, Dmitri E. Fomenko, Hilary G. Morrison, Mitchell L. Sogin, Lawrence A. Klobutcher, Dolph L. Hatfield, and Vadim N. Gladyshev
[5] The functional readthrough extension of malate dehydrogenase reveals a modification of the genetic code ; Julia Hofhuis, Fabian Schueren, Christopher Nötzel, Thomas Lingner, Jutta Gärtner, Olaf Jahn, and Sven Thoms
[6] Linguistic Features of Noncoding DNA Sequences, R. N. Mantegna, S. V. Buldyrev, A. L. Goldberger, S. Havlin, C. K. Peng, M. Simons, and H. E. Stanley, Phys. Rev. Lett. 73, 3169 – Published 5 December 1994
Xem thêm:
Bộ Công an đang xây dựng dự thảo Luật Tổ chức cơ quan điều tra…
Gần đây, giáo sư Dư Mậu Xuân viết rằng “việc tiến hành giao lưu học…
Gần đây, một chiếc máy bay hạng nhẹ đã đâm vào biểu tượng cao nhất…
Phát biểu với các phóng viên tại Phòng Bầu dục, ông Trump thừa nhận sự…
Nhiều chính trị gia cho rằng một số công dân Trung Quốc cố tình sang…
Máy bay ném bom tàng hình B-2 Spirit là loại máy bay duy nhất hiện…
{kind=link}
{kind=link}
{kind=link}
{kind=link}